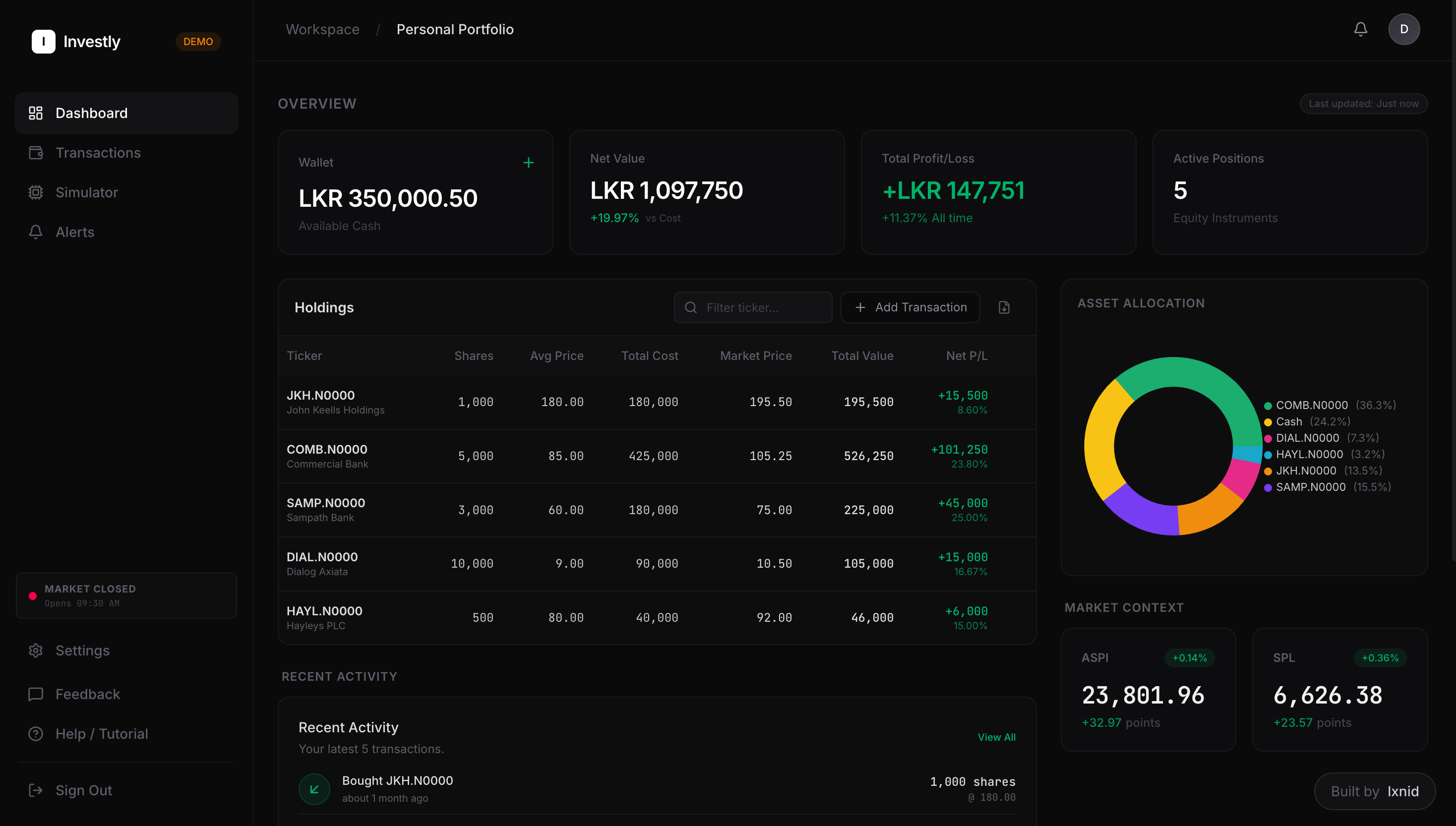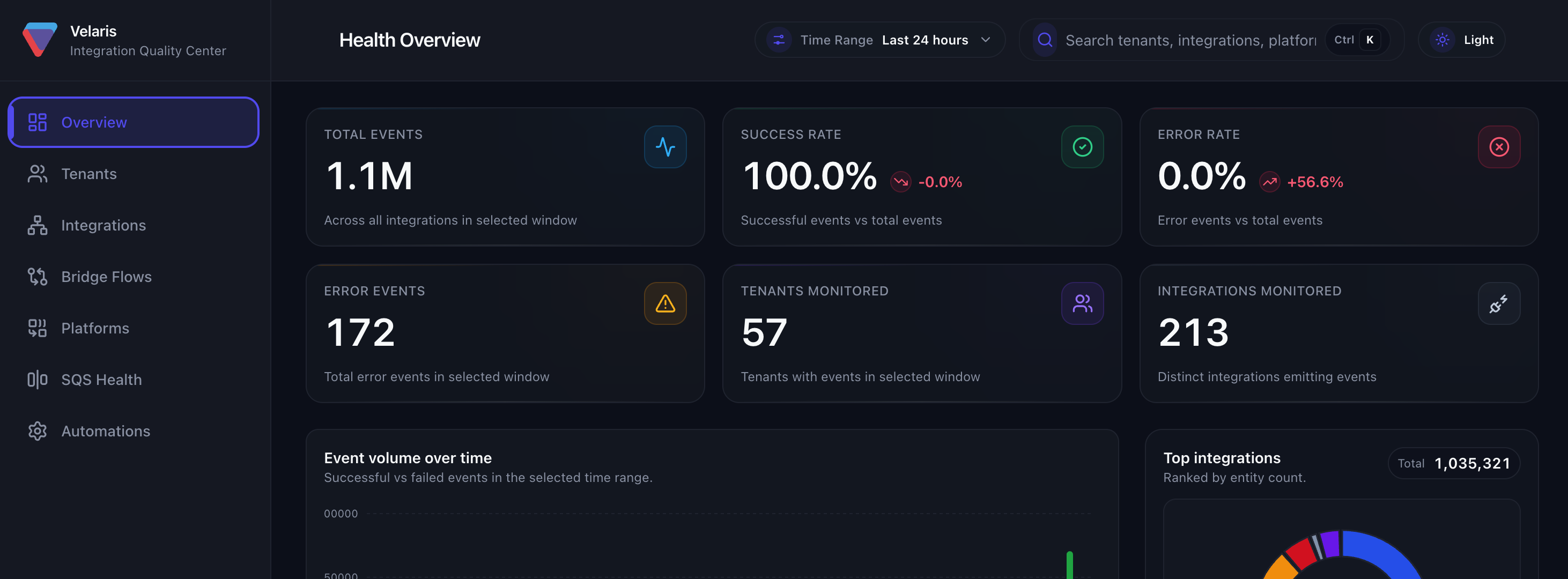
AWS Health Monitoring Dashboard
(2024 (6-month internship))
Serverless monitoring infrastructure that cut AWS debugging time by 90% — built in production for a UK B2B SaaS company using Lambda, EventBridge, and AI-powered log normalization.
During my six-month internship at Velaris.io — a UK-based B2B SaaS company building customer success software — I designed and built a serverless health monitoring infrastructure that reduced AWS debugging time by 90%: from roughly 20 minutes per incident down to 2 minutes. This was a production system. Real engineers on a real team depended on it daily.
The Problem
The engineering team at Velaris was running into a recurring friction point: when something went wrong in the AWS environment, piecing together what happened meant manually digging through raw CloudWatch logs across multiple services. There was no unified view, no intelligent normalization, and no fast path from 'something is broken' to 'here's exactly what happened and where.' Debugging time was averaging 15–20 minutes per incident — time that added up across a distributed team.
What I Built
I built a serverless monitoring pipeline using AWS Lambda and EventBridge that captured events across services, normalized log data (including AI-powered log normalization to surface relevant signals from noisy output), and fed into a Health Monitoring Dashboard that gave the team a single, readable view of system state.
Architecture: AWS Lambda functions for log ingestion and processing, EventBridge for event routing across services, CloudWatch Metrics and Logs Insights for data aggregation, AI-powered normalization layer to parse and classify log signals, Dashboard UI for real-time system health visibility.
The Outcome
Debugging time: 20 minutes to 2 minutes (90% reduction).
Resolved a significant CloudWatch cost spike incident by identifying and optimizing queries that were scanning disproportionate volumes of data.
Delivered a system the team adopted into their daily workflow.
What I Learned
This project fundamentally changed how I think about software engineering. Building something that a production team depends on is a completely different experience from building for yourself. Every architectural decision has downstream consequences. Cost matters. Reliability matters. And the gap between 'it works on my machine' and 'it works in production' is where real engineering happens. Working within a remote UK team also taught me how professional engineering operates across time zones — async communication, code reviews, decisions made through documented rationale rather than hallway conversations.